

Introduction
Time series is nothing but a sequence of values that are indexed in time order. That simple structure has made it very easy to collect in almost all business activities. Hence, time series have become such a widespread commodity in today’s Advanced Analytics that every data-driven organization uses them to gain insight about its business practices. Saying that, the abundance and simple structure of time series shouldn’t deceive you. Modeling objectives for time series forecasting can differ drastically from one business problem to another. This blog post is going to explain major forecasting objectives and their associated use cases in the real world setups.
Use Case 1: Precision Forecasting
Perhaps, this is the most conventional use case of time series modeling. Application of this use case spans from forecasting the specific number of daily users to high level warehouse storage capacity. It can also accommodate a broad range of horizons from short term hourly API requests to long term annual revenue forecast. The main objective of precision forecasting is to forecast future outcomes with the maximum accuracy. Almost all forecasting methodologies are initially developed to achieve this objective.

Figure 1: Example of a precision forecasting model
The common workflow for univariate precision forecasting includes data preprocessing and transformations in tandem with model selection, model tuning and sometimes ensembling. If it is possible to add more information to the solution and train a multivariate model, data enhancement will also be added to the workflow. All aforementioned steps can be done either manually or by leveraging AutoML packages like PyCaret, Dart and AutoTS which can handle most of these steps automatically. However, reaching maximum accuracy still requires a dedicated business analyst/data scientist with great domain knowledge that can validate the initial outputs and revise intermediate steps to generate high quality results for each forecast.
Use Case 2: Scenario-Based Forecasting
Due to their single dimension, time series are inherently susceptible to be modeled without enough context. Multivariate approaches try to overcome this drawback by enhancing the learning process and bringing more dimensions to the model. However, seasoned forecasters are well aware of the fact that no matter how much effort is put into precision forecasting, there will be times that things are completely out of hand. Inaccurate forecasting outcomes might happen either because of a black swan event or as a consequence of an unexpected change in a known external factor.
Black swan events by definition are unpredictable. For instance, when Covid-19 first hit, almost all business forecasts missed it. However, right after its first appearance, it became a known factor with significant effect on the target variable. Scenario-based forecasting provides a framework for businesses to leverage this extra piece of information into their decision-making process in a practical way.
In particular, any organization with intent to maintain a high level of availability and reliability must have a set of contingency plans in place to mitigate unexpected situations. In scenario-based forecasting, the main objective is to determine how an external factor would affect the target timeseries. To do that, a known time varying external factor (regressor) is being incorporated into the model. The main assumption here is to have a good intuition about the regressor’s future behavior. This setup gives the modeler a unique capability to create different what-if scenarios with various viabilities. Then, the modeler can forecast the target variable under those scenarios for a given horizon and see how changes on the regressor will affect the outcomes.
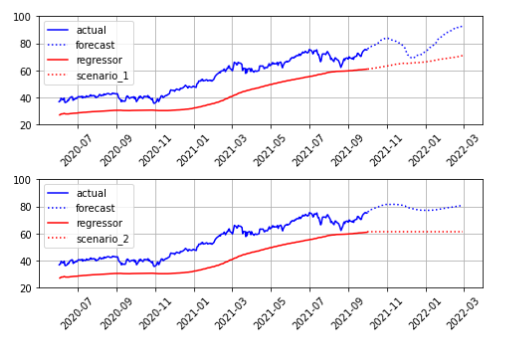
Figure 2: Effect of different scenarios on forecast outcomes
Although scenario-based forecasting can be considered as an extension to precision forecasting and introducing meaningful regressors can significantly improve model accuracy, only a few forecasting methodologies can handle external regressors. Similar to precision forecasting, scenario-based forecasting also needs a dedicated data analyst/scientist with great domain knowledge to build reasonable scenarios in order to reveal valuable insight for strategic planning and risk management or sensitivity analysis.
On another note, most of the time these regressors should be only seen as driver factors for the target variable. Specifically, regressors shouldn’t be mistaken for causality, which highlights the significance of regressor selection. For instance, real estate demand might be affected by interest rates but not caused by it.
Use Case 3: Batch Forecasting
The two previous use cases are mostly about making forecasts for a few time series that are considered as high value targets for the business. However, many data-driven businesses also need a large number of daily forecasts at different levels which might range from a few hundreds to hundreds of millions! The results of these forecasts might also be used in a bottom-up aggregation for total demand calculation or in a top-down setting for resource allocation. Regardless of the application, it is evident that forecasting at this scale can not be done manually. The main objective here is to build an automated process to generate forecasts at large scale with minimum acceptable accuracy at individual time series level while achieving maximum accuracy at aggregate level. Depending upon the number of forecasts and required accuracy, there are three major approaches for batch forecasting:
3-1 Naive Methods
Naive methods are widely being used when a large number of point approximations are required as initial numbers. In this use case, reaching a high level of accuracy is not a major concern since these point approximations are just starter values and most probably being adjusted at operation level. These approximations can be generated by applying a single or a combination of naive methods like last value, moving average, seasonal average or drift on time series. Despite their simplicity, these methods can show decent performance for estimating non-sensitive target variables at aggregate level.
For instance, a CPG company has been successfully using a seasonal naive method for reloading more than 4.5 million vending machines. In this business problem, the exact point estimate for each vending machine is not as important as the truck load estimate, which is the aggregate of multiple vending machines in the same neighborhood. Interestingly once covid hit, the company was able to easily adjust the demand at local distributed centers by delivering only a fraction of their estimate for commercial sites.
3-2 Series of Precision Methods
This approach basically applies one of the precision forecasting methodologies to all time series in the batch. So any increase in the number of time series directly translates to computation time increase. Although with O(N) time complexity, this approach is not considered as highly scalable but parallel implementation of it can handle hundreds to thousands of time series. The major challenge with this approach is the necessity of custom data processing and hyper parameters tuning for all generated models. As we discussed earlier, precision methods need dedicated data transformation and hyper parameter tuning, which is in contrast with batch forecasting objectives to be scalable and automated. There are few strategies to address these issues:
Running a clustering algorithm to identify time series with comparable characteristics and applying a set of similar data preprocessing and hyper parameters to them. Dynamic Time Warping (DTW) and statistical feature extraction are two major approaches that can be used in this context to cluster time series.
For a more diverse set of time series, it is possible to use a meta learning approach. The meta learning employs ML/DL model to recommend a proper set of hyper parameters for a given forecasting method based on the time series characteristics features. Major challenge in training a useful meta learning model is to collect a rich dataset of different time series characteristics as a feature set and their associated well optimized hyper parameters as labels.
Another possibility for forecasting a diverse set of time series is to utilize optimization techniques like Genetic Algorithm or Simulated Annealing to efficiently search the hyper parameters space for best combinations. One advantage of using this approach for batch forecasting is that initial guesses for new time series optimization can be borrowed from previous rounds of optimization. In other words, optimization cycles can learn from different time series. AutoTS is one the best implementations of this approach in python which makes use of Genetic Algorithm to find the best set of transformations and hyper parameters for batch forecasting at scale.
3-3 Machine Learning/Deep Learning Methods
The forecasting approaches that have been discussed so far are suffering from limited scalability or insufficient accuracy and consistency in results. Furthermore, these systems are difficult to maintain. Most of them are incapable of cross learning from other time series or extra non time series data. They are also unable to tackle cold start problems for new input series with short or none history. To overcome these limitations and address new needs, businesses (initially big techs) started to work on ML/DL solutions as an alternative to bring all these requirements under a unified forecasting engine.
Machine learning approaches are not inherently designed to discover sequential order embedded in time series data. Therefore, time dependency should be introduced to the model through lag features and date attributes. A basic feature vector for training a machine learning model is composed of lag values, date attributes, time series characteristics and extra contextual variables. Contextual variables could be all information that can differentiate one data point from others. For instance, information like page views, review rating, search history can be considered as contextual data for e-commerce use cases. In theory, machine learning models are capable of picking up similar patterns from time series characteristics and contextual features. A well built and tuned machine learning model can address the above issues to a certain point. However, there are still two unresolved problems:
- First, this approach has an accuracy cap, which is hard to pass beyond it
- Second, it needs feature engineering efforts that in large scale can become costly
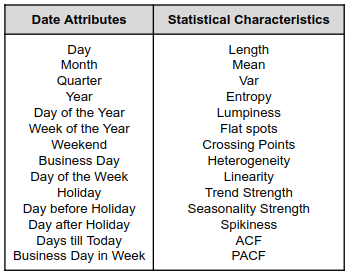
Figure 3: List of common time series features for machine learning forecasting
Deep Learning and specifically Recurrent Neural Networks (RNN) on the other hand are specifically designed to handle sequential data. That doesn’t mean RNN models (LSTM, GRU) can outperform other forecasting methods right off the bat. But leveraging large amounts of data with the recent advancements like transformer-based architecture (encoder-decoder) and attention mechanism have significantly improved DL’s forecasting performance and made them a viable alternative for large scale batch forecasting. To completely unleash the power of deep learning, unstructured data (like product description or review) can also be added to the model in embedded format. This extra contextual input enhances multi-faceted feature extraction and significantly improves model granualirty. Utilizing these approaches in tandem with time series clustering can lead to a robust forecasting engine with high accuracy and efficient feature extraction capability. Packages like PyTorch-Forecasting and GluonTS have already implemented some of these models in user-friendly API formats and made it easy to utilize DL forecasting in production. However, deep learning forecasting is still an active field of research and the forecasting community expects more cross-functional collaborations with other disciplines like Natural Language Processing(NLP), speech recognition and signal processing in the near future.
Use Case 4: Anomaly Detection
Anomaly detection is the last use case that we are going to cover in this post. There are many parametric and non-parametric methods to identify anomaly instances in the time series. These methods are mostly applicable to historical data, thus by definition considered as Descriptive analysis. However many business cases are concerned about real-time anomaly detections or predicting anomaly occurrences in the future, which is categorized under Predictive and Prescriptive Analytics. Both use cases are built on forecasting foundation but there are subtle differences between them.
4-1 Real time Anomaly Detection
IoT operations or businesses with real-time feedback loop can leverage this approach to implement a health monitoring process and a diagnostic tool for their systems. The main idea behind this method is to forecast the future with a model that has been trained on normal historical data. The normal training data can be generated by removing previous anomalies from historical data and filling missing values by one of the imputation methods for time series. After generating the forecast, one can use prediction intervals with a given confidence level as an acceptable range for real time measurement. Therefore, any real time measurement outside the prediction intervals will be pronounced as an anomaly.
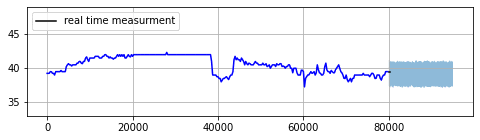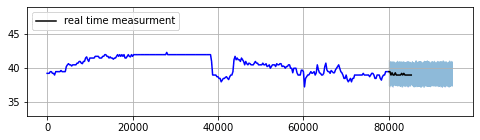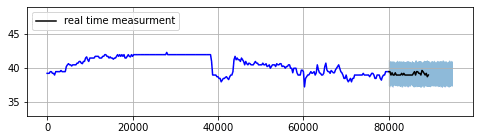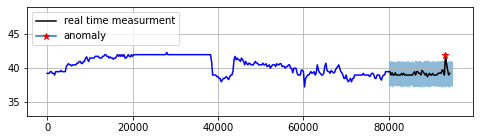
Figure 4: Example of real time anomaly detection
The width of the prediction intervals should be adjusted by system risk tolerance and cost associated with the anomaly event. As it is evident, in this method the objective is to forecast the accurate prediction intervals rather than exact point estimates, which is generally considered as an easier task. Another good news is that this use case usually needs an accurate forecast only in the short term, which is inherently easier to achieve. However, there are few caveats to consider.
For values close to zero it is very difficult to find an actionable prediction interval, especially for the lower bound.
It is technically more challenging to set up a data engineering pipeline and MLOps for digesting a stream of measurement data and training the model more frequently.
4-2 Predicting Anomaly In Future
Businesses ideally intend to stay ahead of events. In that context, predicting any abnormality in the future becomes quite valuable. One classic example for this use case is out-of-stock prediction for CPG companies. This method is mostly similar to real time anomaly detection. So, the prediction intervals for acceptable range are being generated by a model that is trained on normal time series. In parallel, the actual behavior of the system should also be modeled using original time series (before removing anomalies). In this context, any prediction on the original time series that crosses prediction intervals is declared as anomaly.
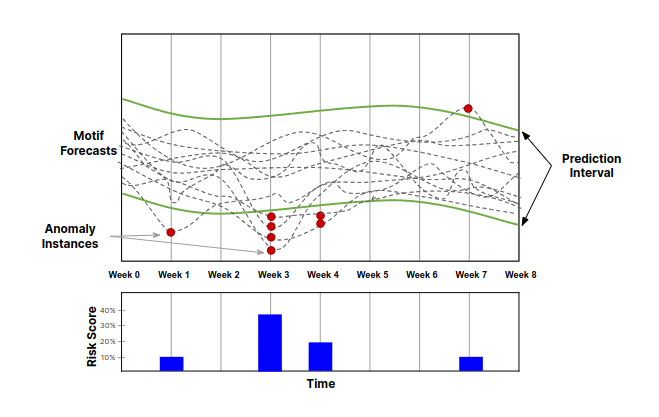
Figure 5: Predicting anomaly in future
Common problem in this approach is that the majority of the precision forecasting methodologies are not able to predict abnormal behavior (A.K.A anomaly) as reliable as trend and seasonality even if anomalies are presented in the historical data. One remedy to this problem could be using methods like motif forecasting that can lay out all possible futures outcomes at once. The result of this forecast then can be used to generate probabilistic anomaly prediction which is more practical for risk management and business planning.
Final Note
In this post, we covered four major use cases of time series forecasting in today’s Advanced Analytics world. Table 1 provides a quick overview of these use cases and their characteristics.
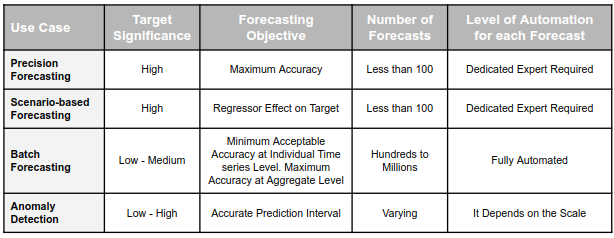
Table 1: Summary of forecasting use cases
Businesses with different Analytics maturity levels can leverage forecasting to improve their decision making process. Organizations that just started developing their advanced analytics capability can utilize Precision / Scenario-based forecasting for robust business planning and goal setting at higher levels. This effort could begin from a few high value targets every month or quarter and gradually expand to more targets and more frequent forecasts. In more mature organizations, this effort can extend to batch forecasting and anomaly detection for hundreds of thousands lower value targets for their day to day operations. That level of data-driven decision making directly translates to higher efficiency and more resiliency of their processes.
